问题描述
基于 Seq2seq 模型来实现文本生成的模型,输入可以为一段已知的金庸小说段落,来生成新的段落并做分析。
引言
文本生成,旨在利用NLP技术,根据给定信息产生特定目标的文本序列,应用场景众多,并可以通过调整语料让相似的模型框架适应不同应用场景。
Seq2seq + Attention
Seq2seq
seq2seq是sequence to sequence的缩写。Seq2seq 是深度学习中最强大的概念之一,从翻译开始,后来发展到问答系统,音频转录等。顾名思义,它旨在将一个序列转换到另一个序列。前一个sequence称为编码器encoder,用于接收源序列source sequence。后一个sequence称为解码器decoder,用于输出预测的目标序列target sequence。
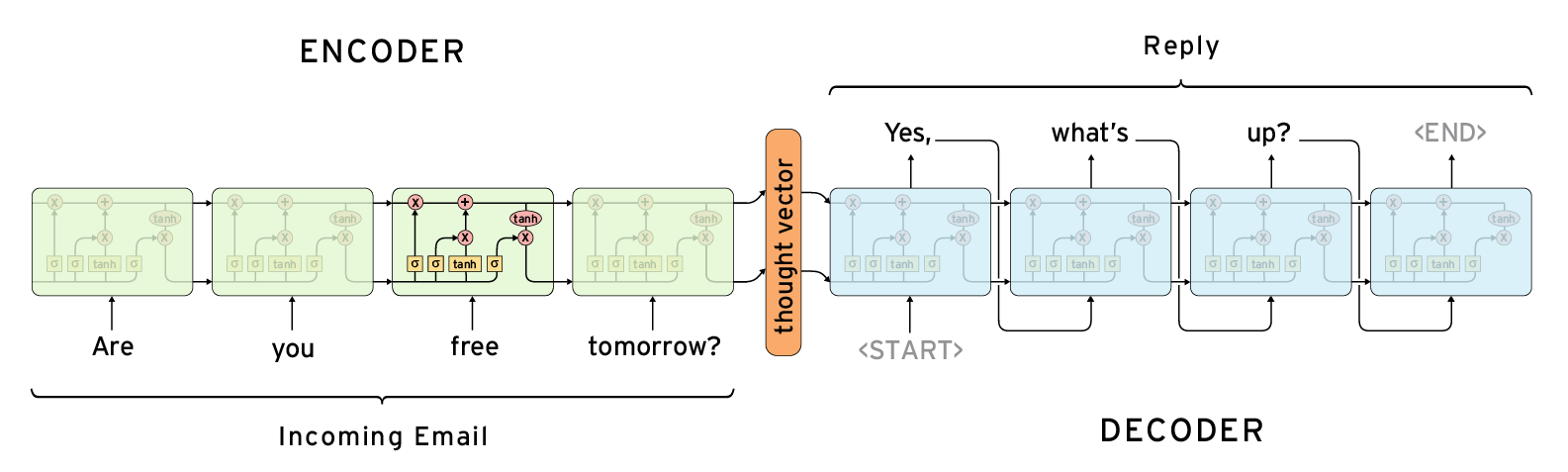
主要思想是它包含一个编码器RNN (LSTM)和一个解码器RNN。一个是“understand”输入序列,解码器解码“thought vector”,并构造一个输出序列。有如下步骤:
- 将源序列输入encoder网络。
-
encoder将源序列的信息编码成一个定长的向量encoder vector。
-
encoder vector被送入decoder网络。
- decoder根据输入的向量信息,输出预测的目标序列。
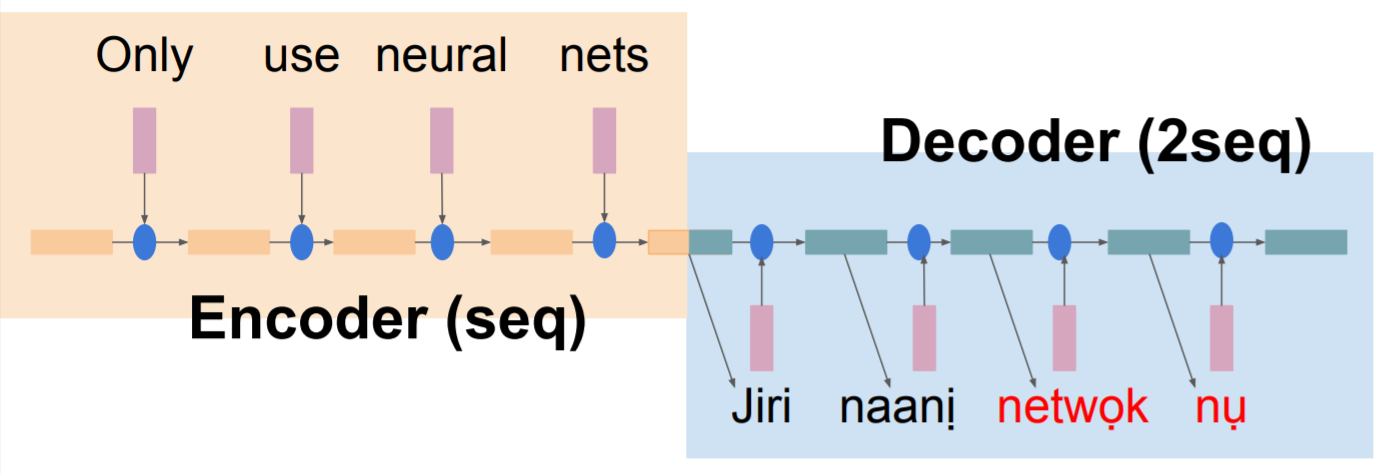
尽管Seq2seq模型备受青睐,但是把一整个文本序列通过encoder压缩到区区一个向量里,很难通过decoder进行完美地没有信息缺失的解码。

此外,由于循环神经网络RNN的特性,源序列中越迟输入的文本,对encoder vector的影响也越大。换句话说,encoder vector里会包含更多的序列尾的文本信息,而忽略序列头的文本信息。所以在很多早期的论文中,会将文本序列进行倒序后再输入encoder(双向RNN),模型测评分数也会有一个显著地提高。
为了让decoder能够更好地提取源序列的信息,Bahdanau在2014年提出了注意力机制Attention Mechanism,Luong在2015年对Bahdanau Attention进行了改进。
Attention mechanism
怎样获取一个合适的语义向量,让decoder能够输出最优的文本。
为了获取这个语义向量
-
首先找出encoder里几个最匹配的词语,
-
然后把这几个词语的语义向量加权求和,
-
最后对加权和做一些修正,得到最终的语义向量。
这也就是Attention机制的核心流程。
在NLP领域,通过decoder预测输出目标序列的时候,希望能够有一种机制,将目标序列当前step,和源序列某几个step的文本关联起来。
以翻译任务为例,将“我爱机器学习”翻译成“I love machine learning.”在decoder输出序列第一个step,我们希望关注输入序列中的“我”,并将“我”翻译成“I”;在第三个step,我们希望关注“机器”,并翻译成“machine”。

这个例子比较简单,我们就会产生一个初步的想法:是不是把源序列中的每个词语单独翻译成英文,再依次输出,就构成目标序列了呢?
但是,如果进一步思考下,我们就会发现两个问题:
- 一词多义:源序列里的同一个词,在输出序列里,可能根据场景的不同,会有不同的输出。
- 序列顺序:源序列和目标序列并不是顺序依次映射的,例如“你是谁?”翻译成“who are you?”,不同语言有不同的语法规则和顺序。
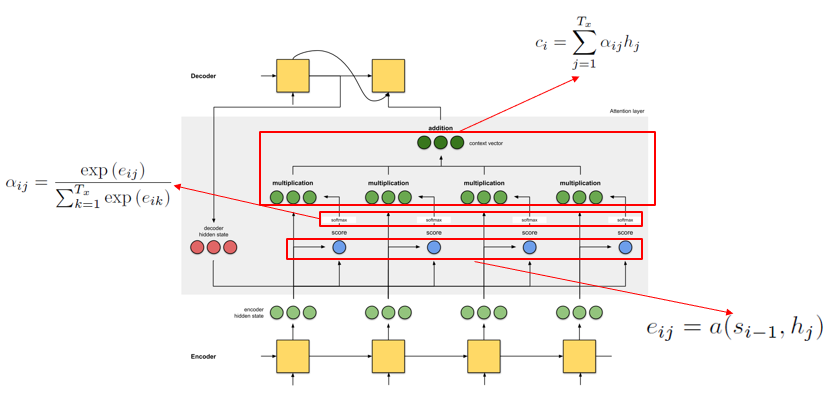
这两个问题也就是Attention机制的关注重点。因为源序列太长了,导致早期的信息无法有效地被传递,所以需要一个额外的通道,把早期的信息送到解码器上。送的时候还不能只送一个词的信息,最好把上下文信息一起给送了。
实验
textgenrnn
本文中,使用 textgenrnn 进行金庸小说的文本生成实验。textgenrnn 是采用 RNN 的方式来实现文本生成的一个简洁高效的库,代码量非常少,又非常易于理解。其架构是采用了LSTM+Attention的方式来实现。如下图所示:
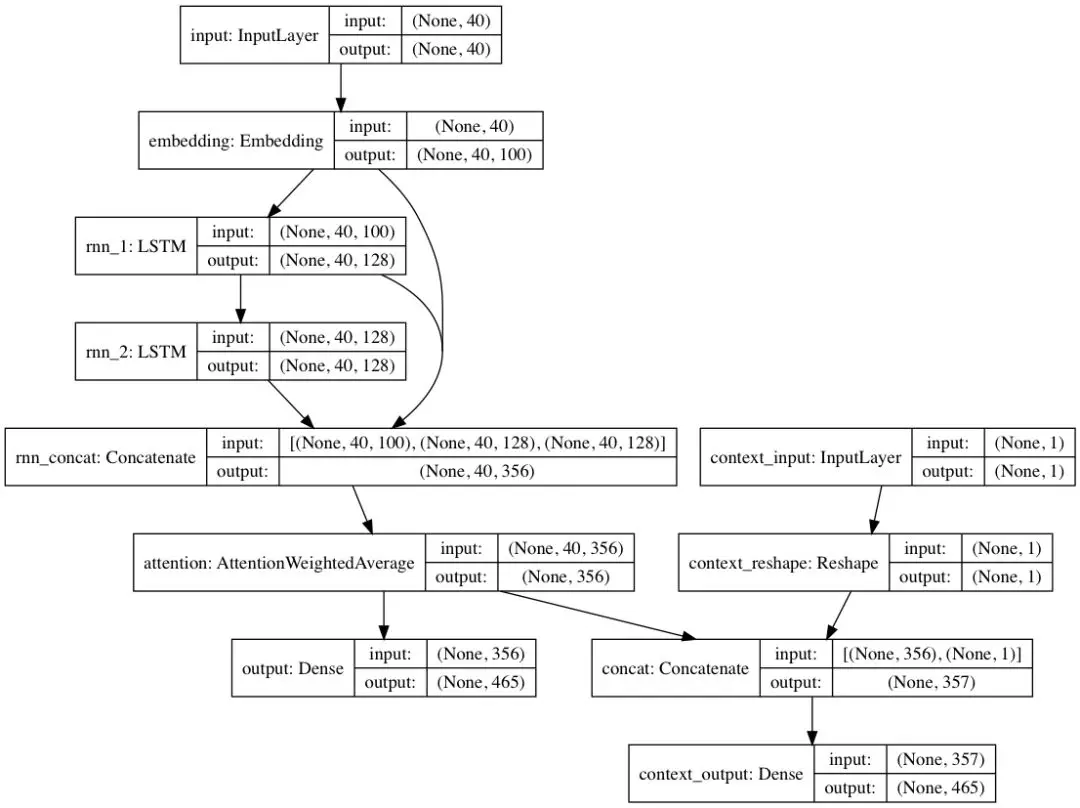
textgenrnn 接受最多 40 个字符的输入,首先每个字符转换为 100 维的词(char)向量,并将这些向量输入到一个包含 128 个神经元的长短期记忆(LSTM)循环层中。其次,这些输出被传输至另一个包含 128 个神经元的 LSTM 中。以上所有三层都被输入到一个注意力层中,用来给最重要的时序特征赋权,并且将它们取平均(由于嵌入层和第一个 LSTM 层是通过跳跃连接与注意力层相连的,因此模型的更新可以更容易地向后传播并且防止梯度消失)。该输出被映射到最多 394 个不同字符的概率分布上,这些字符是序列中的下一个字符,包括大写字母、小写字母、标点符号和表情。而且关键是上述的参数都可以设置。
- 使用注意力权重(attention-weighting)和跳跃嵌入(skip-embedding)等先进技术的现代神经网络架构,用于加速训练并提升模型质量。
- 能够在字符层级和词层级上进行训练和预测。
- 能够设置 RNN 的大小、层数,以及是否使用双向 RNN。
- 能够对任何通用的输入文本文件进行训练。
- 能够在 GPU 上训练模型,然后在 CPU 上使用这些模型。
- 在 GPU 上训练时能够使用强大的 CuDNN 实现 RNN,这比标准的 LSTM 实现大大加速了训练时间。
- 能够使用语境标签训练模型,能够更快地学习并在某些情况下产生更好的结果。
准备数据
本文采用金庸小说作为训练数据。部分数据示例:
1 | |
数据详见:https://share.weiyun.com/5zGPyJX
训练模型
1 | |
还有其他的模型参数可以配置,主要包括以下几项:
1 | |
模型结构:
1 | |
生成数据
1 | |
生成数据样例:
1 | |
从生成的小说数据来看,大部分看上去还是比较正常的,但是也有一些不合理的数据,比如:
1 | |
总结
textgenrnn 是建立在 Keras 和 TensorFlow 之上的,可用于生成字级别和词级别文本。网络体系结构使用注意力加权来加速训练过程并提高质量,并允许调整大量超参数,如RNN模型大小、RNN层和双向RNN。Seq2seq 模型在自然语言处理中取得了较好的结果,与经典RNN结构不同的是,Seq2Seq结构不再要求输入和输出序列有相同的时间长度!
